Salesforce представил семейство моделей xLAM (Large Action Models), предназначенных для оптимизации и автоматизации рабочих процессов отдела продаж. В отличие от LLMs, которые в основном генерируют текст, xLAM выполняет задачи вызова функций (function-calling), что позволяет обновлять базы данных, модифицировать процессы и интегрироваться в бизнес-пайплайны
Технические характеристики семейства xLAM
Модели xLAM разработаны для различных применений в зависимости от требований к производительности и вычислительным ресурсам:
xLAM-1B-fc-r («Tiny Giant»):
Параметры: 1,35 миллиарда
Длина контекста: 16k токенов
Применение: Оптимизирована для использования на устройствах с ограниченными вычислительными ресурсами.
xLAM-7B-fc-r:
Параметры: 6,91 миллиарда
Длина контекста: 4k токенов
Применение: Подходит для академических исследований и маломасштабных приложений.
xLAM-7b-r:
Параметры: 7,24 миллиарда
Длина контекста: 32k токенов
Применение: Промышленные задачи, требующие точного управления более длинными последовательностями данных.
xLAM-8x22b-r:
Параметры: 141 миллиард
Длина контекста: 64k токенов
Применение: Подходит для ресурсоемких задач и крупных предприятий.
Производительность
Модели xLAM показали высокую эффективность. xLAM-7B(fc) занял высокие позиции на Berkeley Function Calling Leaderboard, опередив GPT-4 в задачах вызова функций, что подтверждает их способность эффективно выполнять задачи в реальном времени. Компактная модель xLAM-1B заняла верхние строчки рейтингов в задачах, связанных с использованием инструментов и планированием, демонстрируя, что меньшие модели могут превосходить более крупные в определенных областях.
Исследователи из UC Berkeley и Google DeepMind предложили новый метод оптимизации вычислений на этапе инференса для LLM и продемонстрировали, что увеличение вычислительных мощностей на этапе инференса может быть более эффективным, чем масштабирование параметров модели.
Сравнение методов оптимального масштабирования вычислений на этапе инференса с параллельной выборкой для модели PaLM 2-S*. График показывает, как оптимальное распределение вычислений может значительно превзойти выборку лучшего ответа среди N при использовании в 4 раза меньшего объема вычислений.
Баланс между инференсом и предобучением
Традиционно повышение производительности LLM достигается за счет увеличения размера модели и количества вычислительных ресурсов, затрачиваемых на предобучение. Однако такой подход имеет ограничения, связанные с большими затратами на обучение и эксплуатацию. Исследователи предложили альтернативу: использование дополнительных вычислений на этапе инференса для повышения точности ответов моделей на сложные запросы. Это позволяет развертывать меньшие модели с производительностью, сравнимой с более крупными моделями, но с меньшими затратами на предобучение.
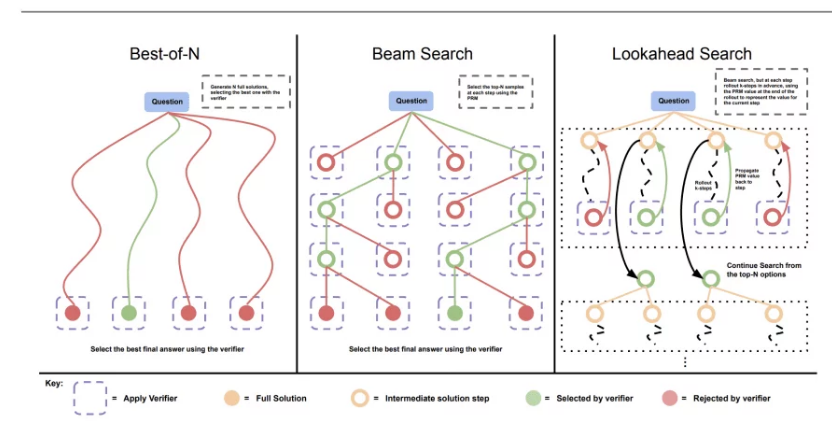
Сравнение методов поиска оптималного ответа:
Основные стратегии оптимизации вычислений на этапе инференса
Исследование рассматривает два основных подхода к оптимизации инференса:
Dense verifier reward models (плотные модели вознаграждения верификатора) Этот метод использует модель, которая верифицирует правильность и релевантность сгенерированных ответов. Модель вознаграждения помогает выбрать наиболее подходящие ответы среди множества возможных вариантов и отправляет их в верификатор.
Adaptive updates to response distributions (адаптивные обновления распределения ответов) Модель динамически корректирует свои ответы, анализируя уже полученные данные и перераспределяя ресурсы в зависимости от сложности задачи.
Lookahead Search улучшает производительность на сложных задачах
Описание: На этом графике показано, что при небольшом объеме вычислений лучшую производительность демонстрирует метод поиска лучшего ответа, однако с увеличением объема вычислений его эффективность снижается.
Lookahead Search использует лучевой поиск с прогнозом на несколько шагов вперед (k-шагов). На каждом этапе модель оценивает ценность решений, анализируя их влияние на последующие шаги. Затем значения наград PRM возвращаются обратно, чтобы корректировать поиск на предыдущих шагах. Это позволяет модели лучше предсказывать качество решений на ранних этапах и значительно улучшает производительность в сложных задачах. Lookahead Search демонстрирует преимущество перед стандартным лучевым поиском и другими методами, особенно при решении задач, требующих многоступенчатого анализа.
Применение адаптивных стратегий для улучшения инференса
В совокупности, модели вознаграждения верификатора, адаптивное обновление распределения ответов и Lookahead Search работают вместе, чтобы оптимизировать процесс инференса. Эти методы не конкурируют друг с другом, а дополняют друг друга, предоставляя модели возможность адаптироваться к различным уровням сложности задачи и эффективно распределять вычислительные ресурсы.
Для простых задач последовательные исправления оказались более эффективными, чем параллельная генерация множества вариантов ответов. В сложных задачах методы, такие как Lookahead Search, дают значительные преимущества за счет прогнозирования на несколько шагов вперед.
Ideogram выпустила обновленную text-to-image модель Ideogram 2.0. Обученная с нуля, Ideogram 2.0 субъективно значительно превосходит конкурентов в точности отображения текста (примеры в статье). Новая бета-версия API позволяет разработчикам бесшовно интегрировать эти возможности в свои приложения
Ideogram 2.0 построена на архитектуре трансформера, которая оптимизирует понимание, генерацию и редактирование текста. Модель включает усовершенствованный механизм внимания, который улучшает её способность обрабатывать и генерировать большие объемы текста, сохраняя при этом высокую связность и точность контекста. Благодаря значительно большему числу параметров по сравнению с предыдущей версией, модель может выполнять сложные задачи, такие как суммирование, перефразирование, перевод и даже креативное написание с большей скоростью и точностью.
Оценка и сравнение
По сравнению с другими передовыми text-to-image моделями, такими как DALL-E и FLUX, Ideogram 2.0 преуспевает в генерации текста, особенно в генерации и редактировании длинных текстов. В ходе наших текстов Ideogram 2.0 показала превосходную плавность и релевантность при выполнении задач по суммированию текста и креативному написанию. Скорость работы не уступает конкурентам — изображение создается за несколько секунд. Несмотря на то что GPT-4 остается лидером в общем понимании, Ideogram 2.0 имеет конкурентное преимущество в специализированных областях, требующих более глубокого взаимодействия с текстом, таких как анализ юридических документов, создание контента и научные исследования, по мнению создателей
Эволюция версии 1.0
Ideogram 1.0 уже неплохо справлялся с генерацей текста, версия 2.0 дает улучшенную точность и скорость обработки текста. Улучшенный механизм внимания модели позволяет ей обрабатывать более объемные и сложные текстовые вводы, не теряя контекста, что делает её гораздо более эффективной для задач, требующих детального понимания и генерации. Кроме того, была доработана способность Ideogram 2.0 понимать нюансы языка — такие как тон, стиль и намерение
VFusion3D — метод генерации 3D-модели из одного изображения, который использует модели диффузии видео, чтобы избежать нехватки данных для обучения. Благодаря дообучению предобученной модели видео-диффузии, VFusion3D генерирует масштабные синтетические наборы данных с несколькими ракурсами, что значительно повышает качество 3D моделей. На входе подается одно изображение, на выходе через 17 секунд модель генерирует меш в формате .obj и видео-демонстрацию весом до 100кб. Протестировать работу модели можно на Huggingface. Код
Результаты
VFusion3D превосходит существующие модели, такие как OpenLRM и LGM, как по 3D согласованности, так и по визуальной точности. Модель достигает более высоких значений CLIP Image и Text Similarity, что свидетельствует о лучшем соответствии входным данным. 90% людей предпочитают результаты VFusion3D другим моделям.
Производительность и скорость
VFusion3D не только создает высококачественные 3D модели, но и делает это эффективно. Она может сгенерировать 3D объект из одного изображения за 17 секунд, что значительно быстрее традиционных методов, которые часто работают медленнее и менее стабильно.
Масштабируемость
Метод позволяет масштабируемо создавать 3D объекты, что идеально подходит для таких отраслей, как игры и AR/VR. Способность быстро генерировать довольно качественные 3D объекты из минимальных входных данных устанавливает новый стандарт в 3D генеративном моделировании.
VFusion3D решает проблему нехватки 3D данных, используя модели видео-диффузии для создания масштабируемых, высококачественных 3D объектов. По мере развития VFusion3D ее способность быстро генерировать согласованные 3D модели из одного изображения, вероятно, станет драйвером дальнейших инноваций в создании 3D контента.